AI speech transcription
Speech recognition with word-level timestamps, speaker diarization, and multi-language detection for accurate transcription.
Transcription, translation, AI voices, and export in one workspace—so you move from upload to a dubbed master without switching tools.
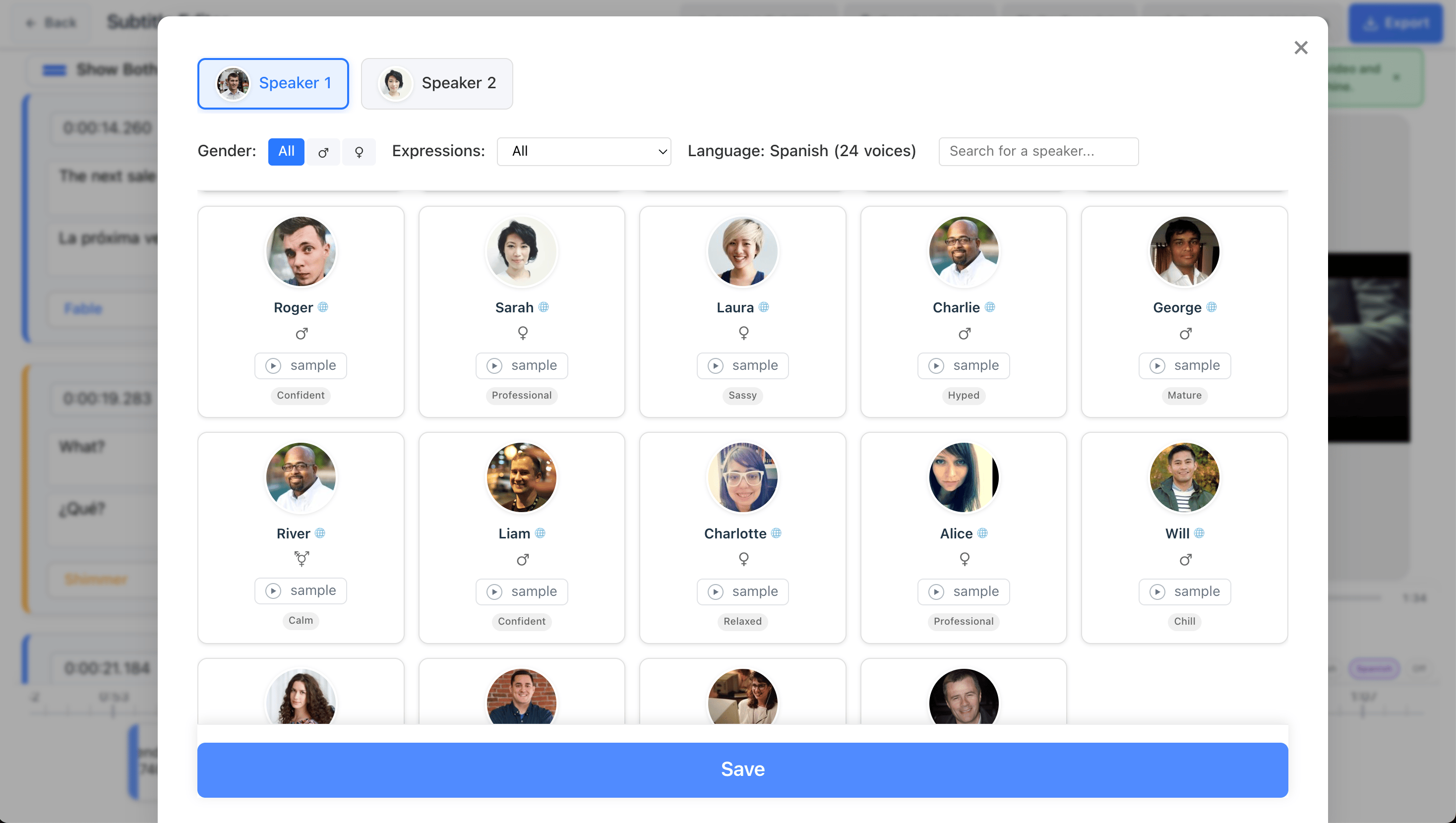
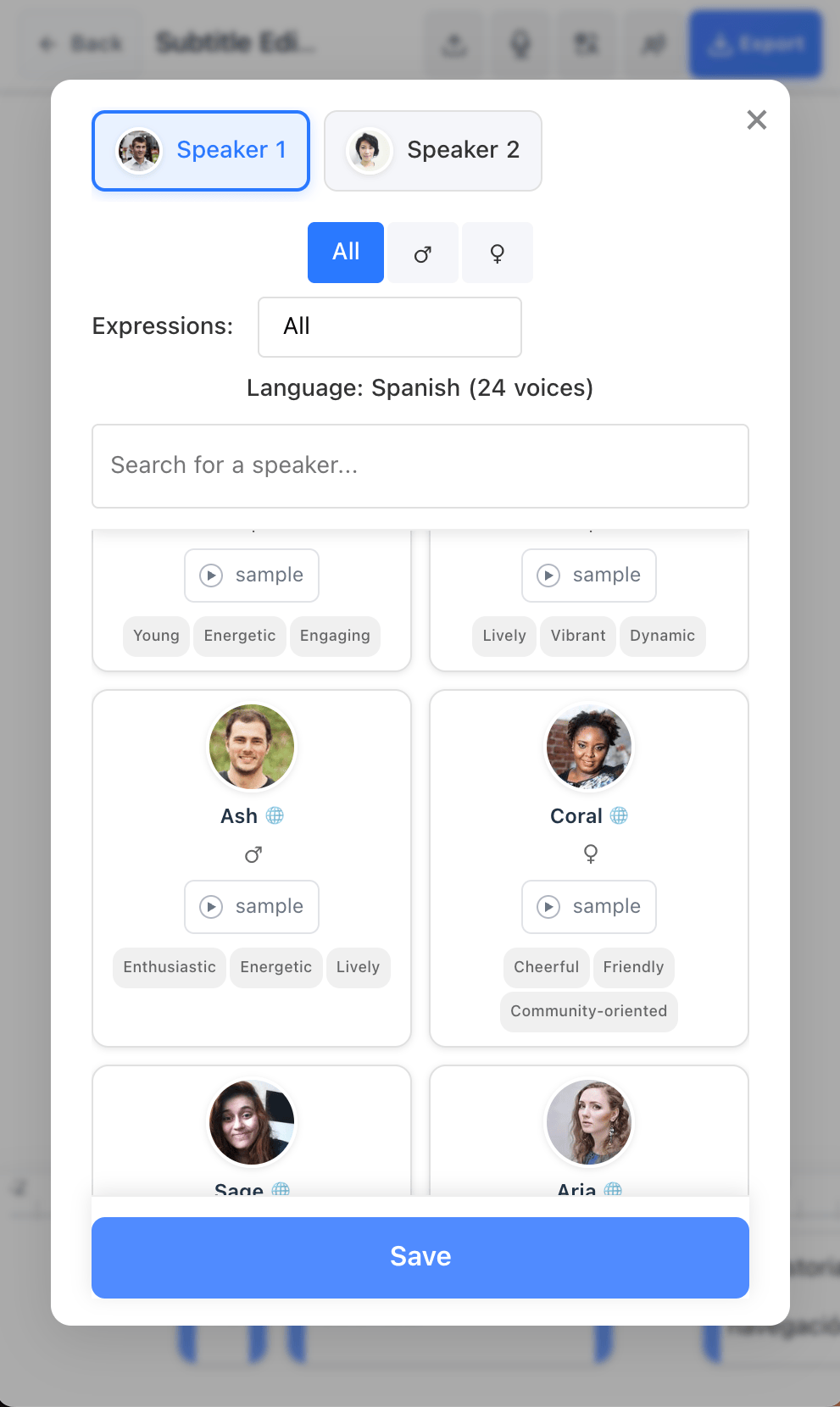
A comprehensive dubbing platform for creators and businesses who want professional results with control over transcription, translation, voices, and mixdown.
Speech recognition with word-level timestamps, speaker diarization, and multi-language detection for accurate transcription.
Translation that preserves cultural context, emotional tone, and meaning across 50+ languages, with room for human review.
Voice synthesis with multiple providers, per-speaker assignment, and custom TTS input for natural-sounding dubs.
Diarization with individual voice assignment—built for interviews, conversations, and multi-character content.
Edit text, adjust timing, refine translations, assign voices, and control exact TTS input at every step.
Broadcast-quality audio with background preservation, precise lip-sync alignment, and professional mixing.
Typical projects finish in under 30 minutes—upload, translate, generate voices, then review and export.
Upload your video; AI extracts audio, transcribes with word-level timing, and identifies speakers.
Translate to your target language while preserving context, tone, and cultural nuance.
Assign AI voices per speaker, tune characteristics, and generate audio matched to timing.
Fine-tune with full human control, preview, and export a dubbed video ready to distribute.
